
Michael Vandi
Mortgage underwriting is notoriously complex, with loan files packed full of documents, numbers, and critical details. Mistakes are costly, and manual processes can slow approvals for weeks.
What if there were a way to extract all the key information instantly and accurately?
In this guide, we’ll explore how data extraction in mortgage underwriting is transforming the process, helping lenders speed approvals, reduce errors, and gain a competitive edge in 2026.
Let AI handle data extraction in mortgage underwriting for you. Book a demo with Addy AI now!
TL;DR
Data extraction in mortgage underwriting turns loan documents into structured data for underwriting review and decisions.
Lenders extract data from 1003s, pay stubs, tax returns, bank statements, and credit reports.
Tools use OCR, NLP, machine learning, and computer vision to read and interpret complex documents.
Automation improves accuracy, reduces errors, and helps lenders manage higher loan volumes.
Addy AI automates extraction, generates summaries, and supports faster underwriting workflows.
What Is Mortgage Data Extraction?
Mortgage data extraction pulls key information from loan files, including Uniform Residential Loan Application (URLA), or 1003 applications, pay stubs, tax returns, bank statements, and credit reports. This data shows a borrower’s income, assets, liabilities, and credit scores.
Manual data entry is slow and error-prone, especially when handling hundreds of pages of sensitive documents. Traditional methods and rule-based systems often misread handwritten notes, complex layouts, or varying document formats.
Automated mortgage data extraction uses intelligent document processing (IDP), natural language processing (NLP), and machine learning (ML) to extract data from multiple document types.
It captures financial information accurately and gives underwriters confidence that loan files are complete and reliable.
Key Documents in Mortgage Underwriting
Underwriters rely on a variety of mortgage documents to assess a borrower’s financial situation and confirm eligibility. Each document provides specific insights needed for accurate decision-making and regulatory compliance.
Key documents include:
Loan applications for employment, property details, and identity verification.
Pay stubs, W-2s, 1099s, and tax forms, which may contain handwritten notes or unusual formats requiring careful review.
Bank statements to confirm net income, account balances, and asset verification.
Loan estimates and closing disclosures outlining interest rates, fees, and cash-to-close amounts.
Credit reports and appraisal documents showing credit scores, liabilities, and property values.
Verification forms and other legal documents, such as employment or asset confirmations.
Manually reviewing these documents takes a lot of time and increases the risk of errors. Understanding the content of each document is essential for accurate mortgage underwriting.
How Mortgage Data Gets Extracted
Data extraction follows a structured flow that turns raw mortgage documents into structured data for the mortgage underwriting process. This is where data collection happens and where key financial data becomes available for review.
Document Intake and Digitization
Mortgage lenders scan or upload files like pay stubs, tax forms, bank statements, and legal documents. Optical character recognition (OCR) reads typed text, and intelligent character recognition (ICR) reads handwritten notes.
For example, handwritten income on a pay stub gets captured immediately. That helps avoid errors when calculating net income and supports accurate income verification documents.
Digitization also creates audit trails that teams can reference during reviews.
Document Classification and Auto-Categorization
ML models organize documents by type, including income documents, bank statements, and closing disclosures. Loan files often include more documents than expected, so this step keeps everything organized early.
A file with multiple bank statements and tax returns gets grouped automatically. Underwriters don’t have to search for the same values in different places, which helps large operations teams avoid manual handling.
Field-Level Data Capture
NLP extracts key data points like income, account balances, interest rates, and fees. It identifies how those values relate to the borrower’s credit profile.
For example, a pay stub may include base income, overtime, and bonuses. The system separates those values so underwriters don’t have to interpret them during manual review.
Validation and Error Detection Rules
Rules flag missing or inconsistent information before files reach underwriting. If income on a W-2 doesn’t match a pay stub, or if closing disclosures don’t align with the loan estimate, the system highlights it.
This step supports data validation and error reduction. It also helps prevent issues that could affect claims processing or create downstream problems.
Output Integration
Validated data flows into loan origination systems (LOS) and other existing systems. Underwriters receive decision-ready data instead of raw files.
At this stage, teams can focus on evaluating the loan instead of preparing it. That keeps the entire workflow organized and easier to manage.
Benefits of Automating Mortgage Data Extraction
Automating mortgage data extraction helps mortgage lenders process loans faster by capturing data from pay stubs, tax forms, bank statements, and other documents.
Underwriters get verified financial information without relying on manual review, which lowers human errors and improves accuracy.
According to the Mortgage Bankers Association, total mortgage origination volume is expected to rise 7.6%, reaching 5.8 million loans in 2026. Lenders will need tools that can handle these higher volumes.
Manual errors in document review can cost thousands per loan, so catching inconsistencies in income verification, net income, and other financial data reduces the rising cost per loan and decreases repurchase risk.
Mortgage loan automation also lowers operational costs. Teams spend less time on repetitive document verification, and intelligent systems keep data collection accurate for multiple documents.
Implementing Intelligent Document Processing in Mortgage Lending
Mortgage leaders rely on intelligent automation to handle the growing volume of documents without increasing manual effort. IDP helps teams manage the entire workflow while keeping data accurate and consistent.
From Document Intake to Structured Output
IDP systems process files as they enter the pipeline. They extract financial data and convert it into structured data that underwriters can use immediately. This keeps information consistent and ready for human review without additional manual processing.
Macro Rules and Exception Handling
IDP systems apply rules to detect missing or inconsistent data. When something doesn’t match, AI agents flag it for review.
For instance, if reported income differs between documents, the system surfaces the issue. Teams can focus on flagged files instead of reviewing every document manually.
Combining Multiple Data Capture Technologies for Accuracy
OCR, ICR, NLP, and computer vision work together to handle different document formats. This combination helps process more documents accurately and keeps financial and legal data aligned.
It also supports fewer defects during underwriting and helps teams avoid repeated manual work.
Integration With Loan Origination Systems and CRM Platforms
IDP systems connect with LOS and customer relationship management (CRM) platforms already in place. Extracted data flows into existing systems without interrupting the process.
This gives teams visibility into each loan and helps them manage higher volume without adding staff.
How Addy AI Improves Intelligent Document Processing
Once lenders implement IDP, the next step is using that data to keep loans on track. This is where Addy AI fits into the workflow.
Addy AI builds on this system by helping mortgage lenders use extracted data in real underwriting workflows. It uses AI models and AI agents to support faster decisions and improve accuracy.
Automated Data Capture and Loan Insights
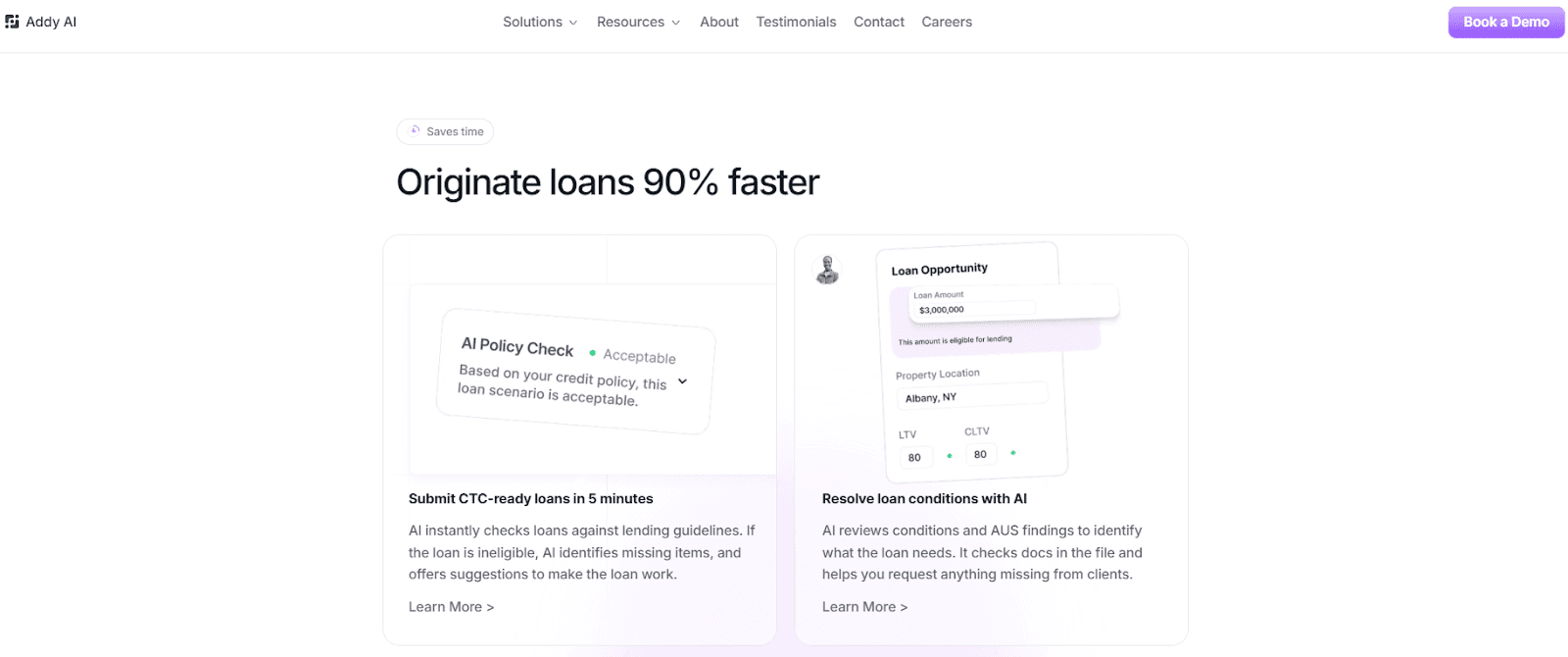
Addy AI extracts and verifies data from unstructured mortgage documents, such as pay stubs, bank statements, tax forms, and 1003s. It uses computer vision to read documents even when formats vary.
It also analyzes documents, emails, and borrower communication to create loan summaries. If a bank statement shows a large deposit, the system highlights it so loan officers can review it right away.
Guideline Search, Questions, and Compliance Checks
Addy AI gives loan officers access to mortgage lending guidelines, including Fannie Mae, Freddie Mac, and non-qualified mortgage (non-QM) lenders. It helps teams compare criteria and find relevant rules.
Users can ask questions in natural language, like identifying authorized signers or checking interest rates. The system also checks for missing data and supports compliance before submission.
Conditions, Follow-Ups, and Workflow Support
Addy AI reviews loan conditions and identifies what’s missing. It builds a checklist of required items and sends follow-ups to borrowers or brokers through automated calls or emails.
It also classifies documents and syncs with LOS and CRM platforms. The Processing Checklist then runs product-specific conditions and prepares files for underwriting in minutes.
Handle High-Volume Underwriting With Addy AI
Mortgage lending isn’t getting simpler. Loan volume is rising, borrower profiles are more complex, and expectations for faster approvals keep growing.
Mortgage teams that rely on outdated processes will struggle to keep up, especially as loan processing demands continue to increase.
The lenders that stay competitive streamline how they handle data and make faster decisions at every stage of underwriting. When workflows stay connected, and information is easy to access, teams spend more time reviewing loans.
Addy AI helps bring everything together. It connects document handling, data insights, and condition management so your team can keep loans progressing without disruptions.
FAQs About Data Extraction in Mortgage Underwriting
What is data extraction in mortgage underwriting?
Data extraction in mortgage underwriting takes key details from loan documents and turns them into structured data. Underwriters use this data to review income, assets, debts and decide if a borrower qualifies.
Which documents are used in mortgage data extraction?
Lenders use documents like 1003 applications, pay stubs, tax returns, bank statements, credit reports, and closing disclosures. These documents show a borrower’s financial picture and help verify the information in the loan file.
What are common red flags in mortgage underwriting?
Underwriters look for issues like income that doesn’t match across documents, large unexplained deposits, or mismatched personal details. Sudden changes in credit or new debt can also raise concerns and trigger a closer review.
Start closing more loans – Book your demo today
Stay ahead of the competition and discover how AI can accelerate your loan origination process, reduce manual work, and help you close more deals in less time. Book a demo today and start experiencing the future of lending.

